Article abstract
This article will introduce the efficient way to use Abaqus python script to access Abaqus odb field outputs. The considerations for Abaqus python scripting are given. A comparison of several unpacking styles to access odb outputs is made. The demonstration code is provided in Github.
Considerations for Abaqus python performance
- Make use of appropriate object sequence unpacking. The style of sequence unpacking can significantly influence the efficiency of your Python scripts.
- Make use of python built-in functions. They are usually optimized for performance.
- Make use of 3rd-party modules. They are usually optimized for performance.
- In general, working with high-level objects is more efficient than working with low-level objects.
- Avoid accessing attributes that require the use of computationally intensive methods. For example: minimize the number of calls to getSubset() and addData() methods.
Comparison of unpacking sytels
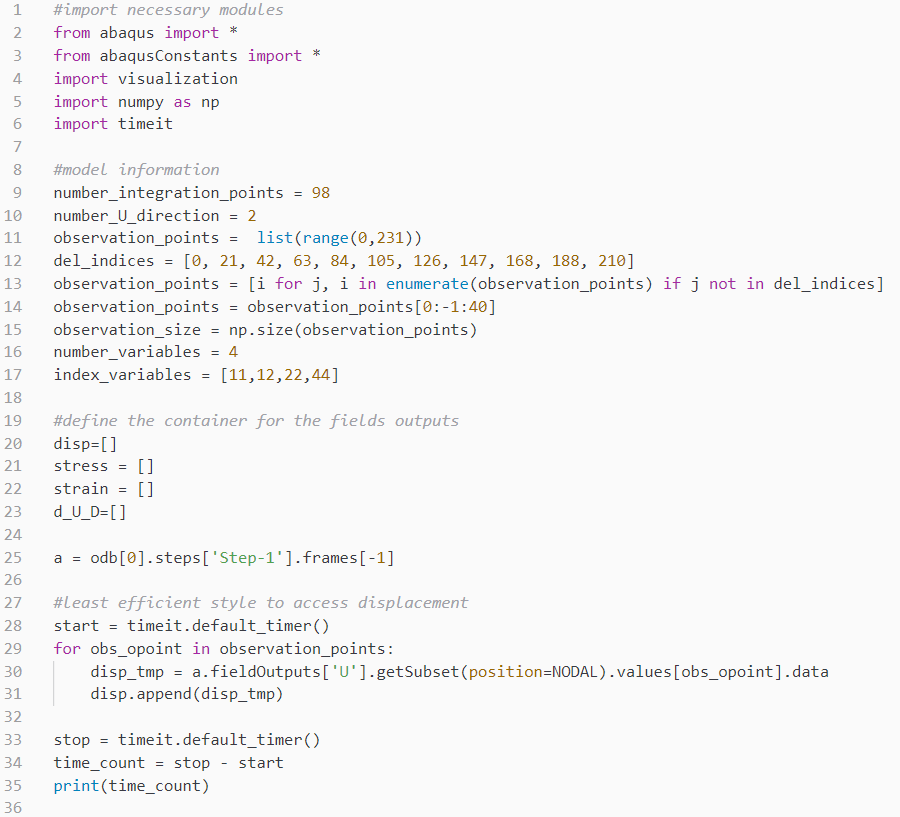
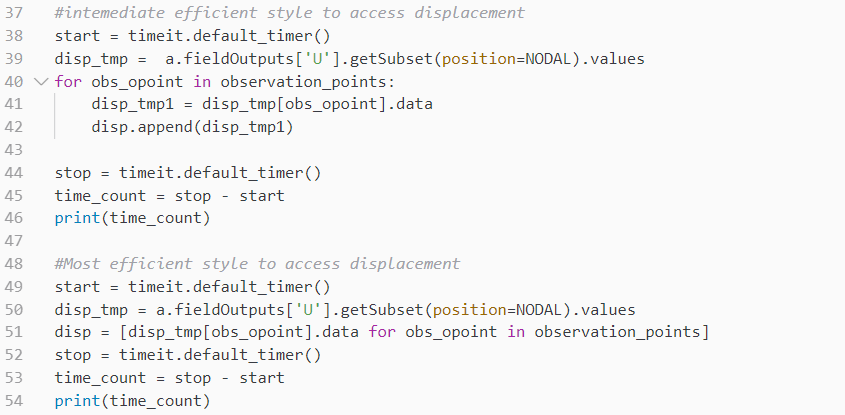
The sequence unpacking style with the Abaqus object model can have a significant influence on performance. Consider the below three methods of access the same stress information:

For the first piece of code, it has to reopen the subdirectories in the odb dictionary every time it accesses stress. Thus, the cost will be significantly expensive for a large model. The second piece of code still needs to open the Value subdirectory. But it is more efficient than the first case. The third piece of code shows the most efficient style. It is recommended to access odb outputs in this style.
Example to access multiple fields outputs
The corresponding materials is accessible is Github: https://github.com/tao364744553/Abaqus-DNN.git